Charting New Waters - MGnify Genomes Marine Catalogue v2.0 Released
spotlight![]() We are excited to announce the release of an updated version of the MGnify Genomes marine catalogue.
This latest release (v2.0) of the marine catalogue contains data from 1628 studies, including genomes from major sampling expeditions such as Tara Oceans, Malaspina, GO-Ship, and Geotraces, amongst others.
We are excited to announce the release of an updated version of the MGnify Genomes marine catalogue.
This latest release (v2.0) of the marine catalogue contains data from 1628 studies, including genomes from major sampling expeditions such as Tara Oceans, Malaspina, GO-Ship, and Geotraces, amongst others.
The inclusion of these datasets resulted in a broad geographical distribution of samples represented in the catalogue, as shown in the image below.
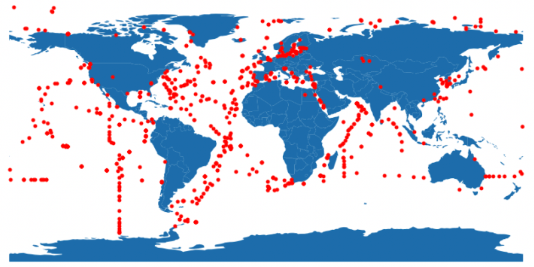
An important advancement in this version of the catalogue is that it is representative of the marine genomes available in the public archives at the time of generation. It includes not only those generated and submitted by MGnify, but also MAGs generated by other groups and submitted to the INSDC, as well as isolate genomes (and MAGs) from marine data as curated by MarDB. All genomes undergo the same filtering for a quality score of QS50 (QS, quality score, defined as completeness - 5 x contamination) resulting in a total of 50,866 genomes (50,634 MAGs and 232 isolates) included in v2.0 of the MGnify Genomes marine catalogue.
This catalogue was generated using v2.3.0 of the MGnify Genomes catalogue pipeline which is available on GitHub and WorkflowHub. Genomes are clustered into 13,223 species-level clusters, with a cluster representative genome defined for each. GTDB-Tk (Genome Taxonomy DataBase Toolkit) is used to assign a taxonomic rank to the clusters, allowing us to also understand the proportion of genomes within the catalogue which can be considered novel with respect to the current release of GTDB. The various statistics for the catalogue are shown in the table below.
| Genomes in catalogue | 50,866 |
| Isolate genomes in catalogue | 232 |
| MAGs in catalogue | 50,634 |
| Species-level clusters | 13,223 |
| Bacterial species-level clusters | 12,133 |
| Archaeal species-level clusters | 1,087 |
| Pangenome clusters | 7,095 |
| Bacterial clusters novel wrt GTDB | 5,260 |
| Archaeal clusters novel wrt GTDB | 536 |
| Non-redundant sequences in protein catalogue | 52,607,289 |
| Protein sequence clusters at 90% amino acid identity | 25,747,277 |
As with all MGnify Genomes catalogues, the data is available to access and query both through the MGnify website as well as via the MGnify API. The catalogue can be browsed as a list of genomes, with the ability to filter on metadata fields, or a taxonomic tree providing access to individual cluster representative genome records. Within the individual genome records there are comprehensive genome statistics, summaries of annotations, and an interactive genome browser allowing interrogation of the various annotation tracks and their genomic context. All results files can be downloaded via HTTP or FTP from the catalogue directory. There are also two sequence-based search options that can be carried out via the website or API. The first is a COBS (COmpact Bit-sliced Signature index)-based query for searching gene sequences against the catalogues. The second is a kmer-based search using Sourmash to allow querying of whole genomes or sets of genomes against the catalogues.
As always we would welcome any feedback you have on this latest version of the marine catalogue, or indeed any aspect of MGnify and MGnify genomes.
 This work was funded by the European Union under the Horizon Europe Programme, Grant No. 101082304 (BlueRemediomics) and Grant No. 862923 (AtlantECO). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the granting authority, the Research Executive Agency (REA). Neither the European Union nor the granting authority can be held responsible for them.
This work was funded by the European Union under the Horizon Europe Programme, Grant No. 101082304 (BlueRemediomics) and Grant No. 862923 (AtlantECO). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the granting authority, the Research Executive Agency (REA). Neither the European Union nor the granting authority can be held responsible for them.