Charting New Waters - MGnify Genomes Marine Catalogue v2.0 Released
spotlight![]() We are excited to announce the release of an updated version of the MGnify Genomes marine catalogue.
This latest release (v2.0) of the marine catalogue contains data from 1628 studies, including genomes from major sampling expeditions such as Tara Oceans, Malaspina, GO-Ship, and Geotraces, amongst others.
We are excited to announce the release of an updated version of the MGnify Genomes marine catalogue.
This latest release (v2.0) of the marine catalogue contains data from 1628 studies, including genomes from major sampling expeditions such as Tara Oceans, Malaspina, GO-Ship, and Geotraces, amongst others.
 In the coming months we will be expanding MGnify Genomes to include Eukaryotic genomes. Take an early look at our plans to enable users to explore Eukaryotic genomes using Anvi’o.
In the coming months we will be expanding MGnify Genomes to include Eukaryotic genomes. Take an early look at our plans to enable users to explore Eukaryotic genomes using Anvi’o. We are excited to announce the launch of
We are excited to announce the launch of 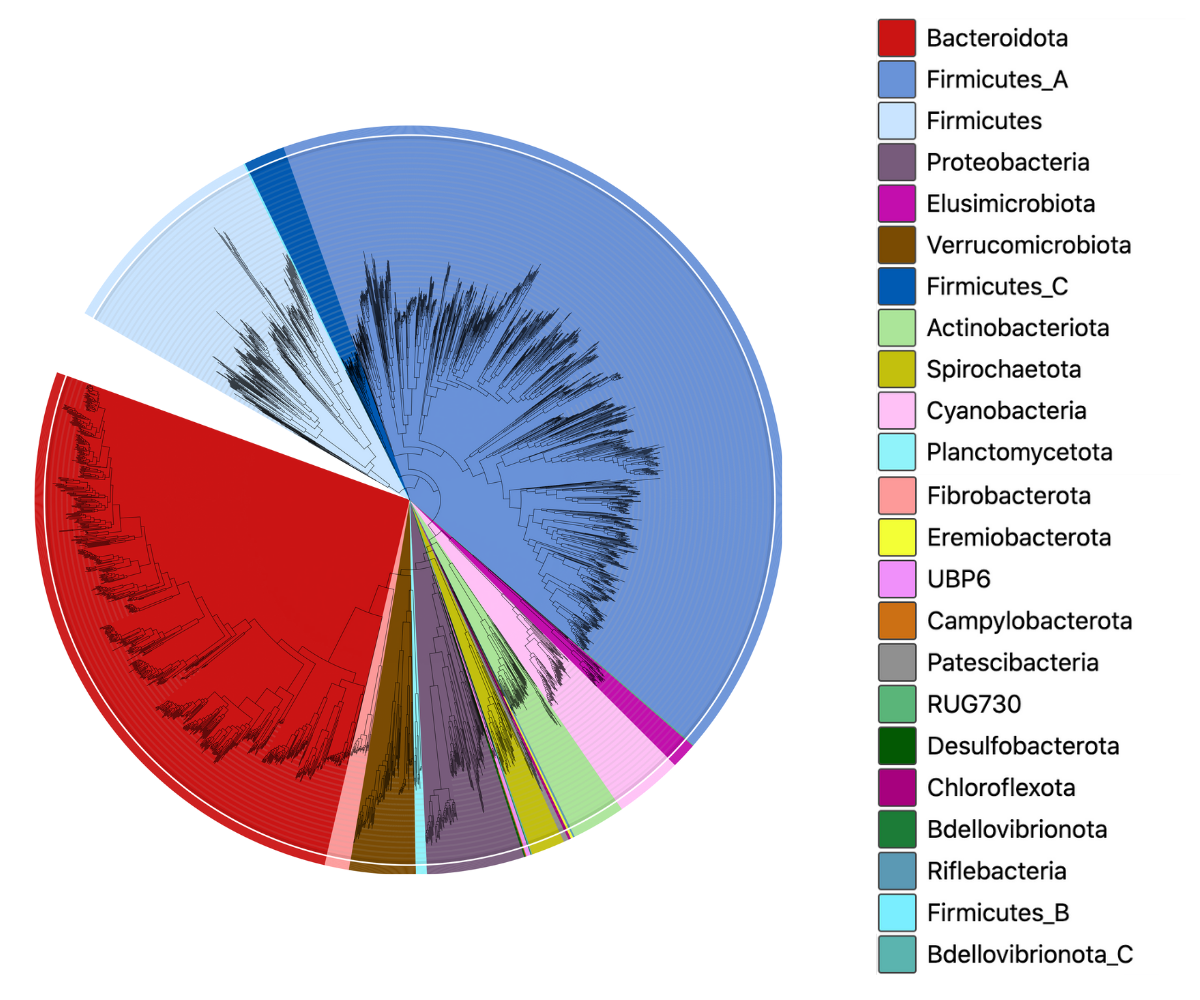 MGnify is delighted to announce the release of our latest
MGnify is delighted to announce the release of our latest 
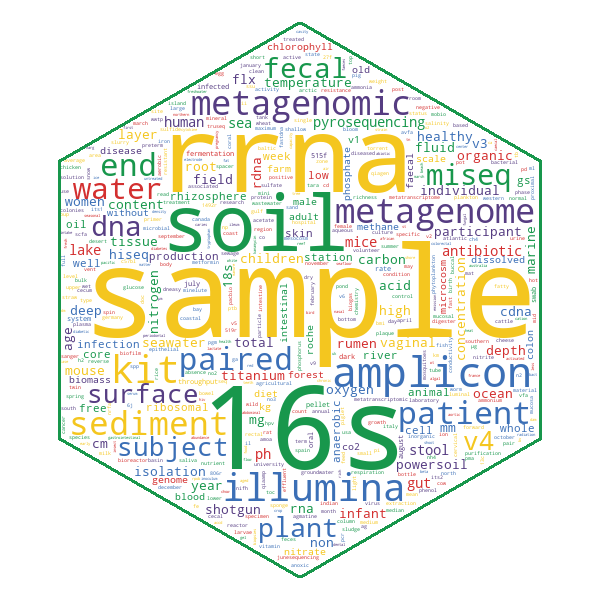 Automated annotations are now available for publications linked to metagenomic studies on MGnify, powered by
Automated annotations are now available for publications linked to metagenomic studies on MGnify, powered by  Need to compile metadata to perform trait associations using our metagenomic data? Interested in correlating species abundance with the origin of the sample to identify organisms associated with a particular environment or state? Try our latest metagenomics toolkit (called: “mg-toolkit”) - a beta version of a tool to enable scientists to download all of the sample metadata for a given study to a single csv file. Simply install as follows:
Need to compile metadata to perform trait associations using our metagenomic data? Interested in correlating species abundance with the origin of the sample to identify organisms associated with a particular environment or state? Try our latest metagenomics toolkit (called: “mg-toolkit”) - a beta version of a tool to enable scientists to download all of the sample metadata for a given study to a single csv file. Simply install as follows:

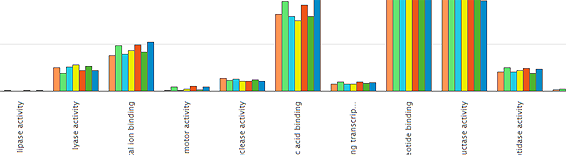 Interested in comparing the functional profile of sequencing runs within a project? Now it is possible, using our comparison tool, which provides analysis based on a slimmed-down subset of Gene Ontology (GO) terms, specially developed to describe metagenomic data.
Interested in comparing the functional profile of sequencing runs within a project? Now it is possible, using our comparison tool, which provides analysis based on a slimmed-down subset of Gene Ontology (GO) terms, specially developed to describe metagenomic data. The microbial population (or microbiome) of the human gut is involved in a wide range of important processes, such as digestion, production of vitamins and other nutrients, detoxification, protection from pathogens, and helping to shape the host immune system. Gut microbial communities represent substantial reservoirs of genetic and metabolic diversity: different people have different types of microorganisms in their gut, and community composition can change over time or with diet.
The microbial population (or microbiome) of the human gut is involved in a wide range of important processes, such as digestion, production of vitamins and other nutrients, detoxification, protection from pathogens, and helping to shape the host immune system. Gut microbial communities represent substantial reservoirs of genetic and metabolic diversity: different people have different types of microorganisms in their gut, and community composition can change over time or with diet. Plankton ecosystems contain a phenomenal reservoir of life: more than 10 billion organisms inhabit every litre of oceanic water, including viruses, prokaryotes, unicellular eukaryotes (protists), and metazoans.
Plankton’s importance for the earth’s climate is at least equivalent to that of the rainforest. Yet only a small fraction of organisms that compose it have been classified and analysed.
Plankton ecosystems contain a phenomenal reservoir of life: more than 10 billion organisms inhabit every litre of oceanic water, including viruses, prokaryotes, unicellular eukaryotes (protists), and metazoans.
Plankton’s importance for the earth’s climate is at least equivalent to that of the rainforest. Yet only a small fraction of organisms that compose it have been classified and analysed.